서론
지금까지 복합인덱스, 명시적 타입 캐스팅 삭제로 매장 조회 기능을 개선했었다.
이번 글에선 의도한 SQL 흐름과는 다른 실제 실행 흐름을 분석하고 최적화를 해보겠다.
문제 코드
// 회원이 찜한 매장 페이징 조회
@Override
public List<MarketRes> findMyFavoriteMarketList(Long memberId, LocalDateTime lastModifiedAt, Integer size) {
return jpaQueryFactory
.select(new QMarketRes(
market.id,
market.name,
market.description,
metro.name.concat(" ").concat(local.name),
market.thumbnail,
favorite.id.isNotNull(),
coupon.id.isNotNull(),
favorite.modifiedAt))
.from(market)
.innerJoin(favorite).on(market.eq(favorite.market)
.and(favorite.isDeleted.eq(false)
.and(favorite.member.id.eq(memberId)))) // 자신이 찜한 매장
.leftJoin(coupon).on(coupon.market.eq(market)
.and(coupon.isDeleted.eq(false))
.and(coupon.isHidden.eq(false))
.and(coupon.createdAt.goe(LocalDateTime.now().minusDays(7)))) // 7일 전 보다 크거나 같은 쿠폰
.innerJoin(local).on(market.local.eq(local))
.innerJoin(metro).on(local.metro.eq(metro))
.where(ltFavoriteModifiedAt(lastModifiedAt) // 회원 자신이 동시간대에 찜할 수 없으므로 lt이다.
.and(market.isDeleted.eq(false)))
.orderBy(favorite.modifiedAt.desc())
.limit(size + 1)
.fetch();
}
해당 코드는 사용자가 찜한 매장을 페이징 조회하는 코드이다.
From market을 통해 매장을 먼저 불러오고 나머지 favorite,coupon 등의 테이블을 조인하는 줄 알았다.
하지만 EXPLAIN ANALYZE를 통해 실행분석을 보니, 해당 코드와는 전혀 다른 실행 흐름이었다.
Limit
└── Nested Loop Left Join
└── Nested Loop Inner Join
└── Nested Loop Inner Join
└── Nested Loop Inner Join
└── Sort (on favorite.modified_at DESC)
└── Filter (member_id, isDeleted 조건)
└── Table scan on favorite
└── Index lookup on market
└── Index lookup on local
└── Index lookup on metro
└── Filter (coupon 조건)
└── Index lookup on coupon
먼저 조인시 가장 먼저 접근한 테이블(Driving Table)이 market이 아니라 favorite이었다!
favorite을 먼저 접근하고, 나머지 테이블들을 조인한 것이었다.
내 생각으론 정렬기준이 favorite의 modifiedAt(수정 시간)을 기준으로 하기 때문인 걸로 짐작한다.
전혀 의도하지 않은 흐름이어서,인덱스를 활용하지 못하고 favorite을 풀스캔, Sort까지 실행하였다.
그럼 먼저, 가독성을 위해 현재 실행되는 흐름을 코드로 먼저 수정해보자.
수정 코드
// 회원이 찜한 매장 페이징 조회
@Override
public List<MarketRes> findMyFavoriteMarketList(Long memberId, LocalDateTime lastModifiedAt, Integer size) {
return jpaQueryFactory
.select(new QMarketRes(
market.id,
market.name,
market.description,
metro.name.concat(" ").concat(local.name),
market.thumbnail,
favorite.id.isNotNull(),
coupon.id.isNotNull(),
favorite.modifiedAt))
.from(favorite)
.innerJoin(favorite.market, market)
.innerJoin(market.local, local)
.innerJoin(local.metro, metro)
.leftJoin(coupon).on(coupon.market.eq(market)
.and(coupon.isDeleted.eq(false))
.and(coupon.isHidden.eq(false))
.and(coupon.createdAt.goe(LocalDateTime.now().minusDays(7))))
.where(
favorite.isDeleted.eq(false)
.and(favorite.member.id.eq(memberId))
.and(ltFavoriteModifiedAt(lastModifiedAt))
.and(market.isDeleted.eq(false))
)
.orderBy(favorite.modifiedAt.desc())
.limit(size + 1)
.fetch();
}
Driving Table이 favorite이기 때문에 from favorite으로 변경했고 where에서 보이는 조건들을 한 눈에 볼 수 있도록 하였다.
옵티마이저가 테이블 풀스캔을 하는 방식은 인덱스를 활용하는 방식과 성능면에서 차이가 없거나 인덱스를 쓰지 못하는 상황이다.
where절에 isDeleted, memberId, modifiedAt이 조건에 들어가는 걸로 보아 인덱스를 쓰지 못해 테이블 스캔을 하는 걸로 보이고, 정렬 기준이 id가 아닌 modifiedAt이므로 정렬도 인덱스를 활용하지 못한다.
@Index(name = "idx_favorite_paging", columnList = "member_id, isDeleted, modified_at DESC")
따라서 where절의 조건과 정렬을 인덱스를 이용할 수 있도록 복합 인덱스를 생성했다.
결과
변경 전
└── Sort (on favorite.modified_at DESC)
└── Filter (member_id, isDeleted 조건)
└── Table scan on favorite
변경 후
└── Index Lookup on favorite using idx_favorite_paging (by member_id = 201901658, isDeleted = false)
인덱스를 사용하여 조회하고 정렬도 따로 하지 않는 것을 볼 수 있다.
개선 전
-> Limit: 11 row(s) (cost=28300 rows=11) (actual time=0.638..0.772 rows=11 loops=1)
개선 후
-> Limit: 11 row(s) (cost=379 rows=11) (actual time=0.095..0.314 rows=11 loops=1)
실행계획의 cost 차이도 28300 -> 379로 대략 74배 차이가 나며, 매우 큰 성능 개선효과가 나타났다.
테스트
favorite의 데이터가 24000개 가량 있는 상태에서 응답 속도의 차이를 한번 보았다.


82ms -> 50ms로 확 낮아진 걸 알 수 있다. 더 정확한 테스트를 위해 부하테스트를 해보자.
총 2000번의 요청을 날려보았다.

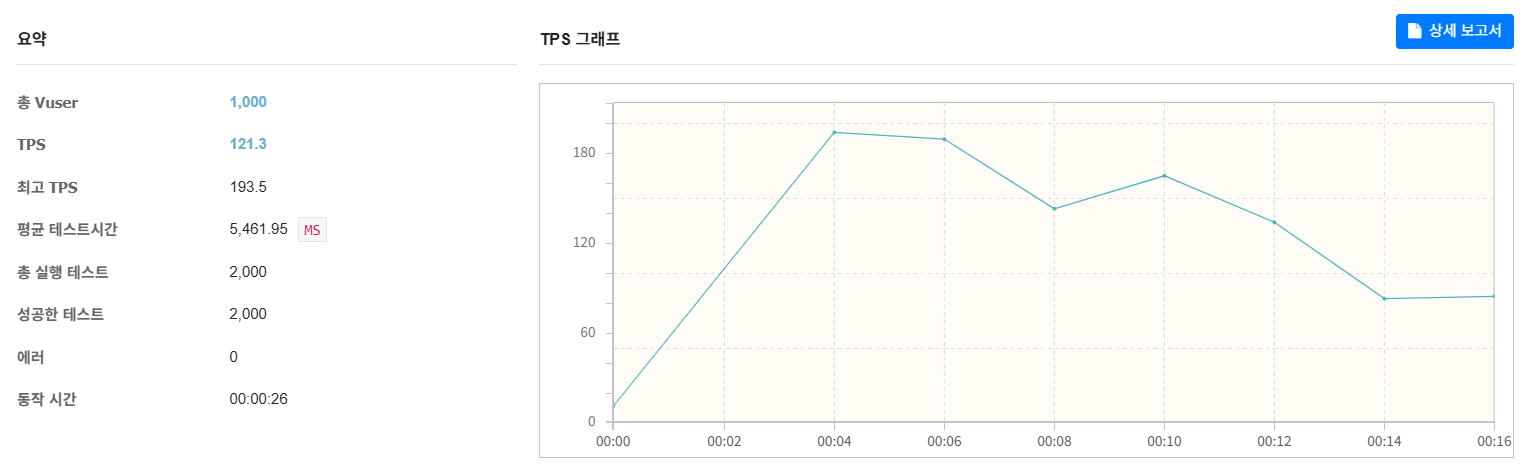
평균 TPS가 61 -> 121로 두 배 차이가 나는 것을 볼 수 있다.
마무리
아직 많이 부족하지만, 세 편의 글을 쓰면서 쿼리를 어떻게 최적화해야 할지에 대한 감이 조금씩 잡히는 것 같다.
이제 어플이 출시되면, 모니터링을 통해 지표를 확인하고 또다시 개선해 나가야겠다.
'쿠러미' 카테고리의 다른 글
| [쿠러미] Redis 캐싱을 통한 성능 개선 (1) | 2025.05.28 |
|---|---|
| [쿠러미] 쿼리 최적화를 통한 매장 조회 성능 개선 - 2 (0) | 2025.05.25 |
| [쿠러미] 쿼리 최적화를 통한 조회 성능 개선 시작 - 1 (0) | 2025.05.24 |
| [쿠러미] Redis 분산락 구현, 비관적락 성능 비교 (0) | 2025.05.14 |
| [쿠러미] 쿠폰 발급 시 (동시성 제어 + 중복 체크) 문제해결 (0) | 2025.05.11 |



