서론
이전 글에서는 실행 계획을 통해 쿼리를 분석하고 복합 인덱스를 통해 매장 조회 성능을 개선했었다.
이번 글에서는 서비스에서 특정 카테고리(예: `FOOD`)에 속한 마켓 목록을 조회하는 쿼리에 문제가 있는 걸 고쳐보겠다!
Enum 필드 인덱스 미적용(카테고리 별 매장 조회)
@Table(name = "category",
indexes = {
@Index(name = "idx_category_major", columnList = "major") // major 컬럼에 인덱스 추가
})
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private Major major;
}
major라는 Enum 컬럼에 인덱스를 추가해 매장 조회 시 WHERE 절에서 카테고리 필터링 속도를 빠르게 하도록 의도했다.
하지만, EXPLAIN ANALYZE를 통해 분석 결과를 보니,
-> Filter: (cast(c2_0.major as char charset utf8mb4) = 'FOOD') (cost=0.25 rows=1) (actual time=0.00481..0.00492 rows=1 loops=11)
-> Single-row index lookup on c2_0 using PRIMARY (id = m1_0.category_id) (cost=0.25 rows=1) (actual time=0.00286..0.00289 rows=1 loops=11)
major 컬럼에는 인덱스가 있음에도 불구하고, 필터 조건이 인덱스를 활용하지 못하고 후처리(Filter 단계) 에서 처리되고 있음을 알 수 있다.
.where(ltMarketId(marketId)
.and(market.isDeleted.eq(false))
.and(category.major.stringValue().eq(major)))
알아보니, major는 Enum 타입인데, stringValue()를 통해 Enum을 문자열로 변환한 후 비교하고 있다.
그 결과 JPA → SQL 변환 과정에서 다음과 같은 형 변환(CAST) 이 발생했다:
형 변환이 포함된 조건은 인덱스를 사용할 수 없다.
인덱스는 컬럼의 원본 데이터 형식을 기준으로 작동하기 때문에, cast(...)로 인해 인덱스가 무시되고 전체 데이터를 순차 탐색하게 된다.
@Enumerated(EnumType.STRING)을 통해 enum 값을 db에 String 값으로 저장하기에 String으로 변환한다음 비교를 해주어야겠다고 생각했었지만, JPA가 내부적으로 Enum → String 변환을 자동으로 처리해주기 때문에, 직접 변환할 필요가 없다!
해결
.where(category.major.eq(Major.valueOf(major)))
굳이 String으로 변환하지않고 Enum 자체를 직접 비교하면 JPA가 자동으로 String으로 처리해주고,
SQL에서도 cast() 없이 직접 비교가 가능해진다.
결과
Filter: (c2_0.major = 'FOOD') (cost=0.25 rows=1) (actual time=0.00257..0.00267 rows=1 loops=11)
-> Single-row index lookup on c2_0 using PRIMARY (id = m1_0.category_id) (cost=0.25 rows=1) (actual time=890e-6..917e-6 rows=1 loops=11)
캐스팅을 하지 않고 바로 비교를 하기 때문에,
(actual time=0.00481..0.00492 rows=1 loops=11) -> (actual time=0.00257..0.00267 rows=1 loops=11)로 두 배 빨라졌다.
하지만, 여전히 major 인덱스를 활용하지 못하고 있다.
이유
category는 한 매장에 대해 하나의 카테고리만 존재하기 때문에 category의 id로 조인을 해왔을 때 하나의 row만 조회가 된다.
따라서 major 인덱스를 생성해도 어차피 id로 단일 row 매칭되므로 major는 인덱스에서 활용되지 않고 필터 단계에서 평가되는 것이다.
id 조인만으로도 충분하니 major 인덱스를 삭제하도록 하겠다!
성능
사용자 1000명이 2번 카테고리 별 매장 조회 요청을 날려 총 2000번의 요청을 하는 부하테스트를 해보았다.
변경 전

변경 후
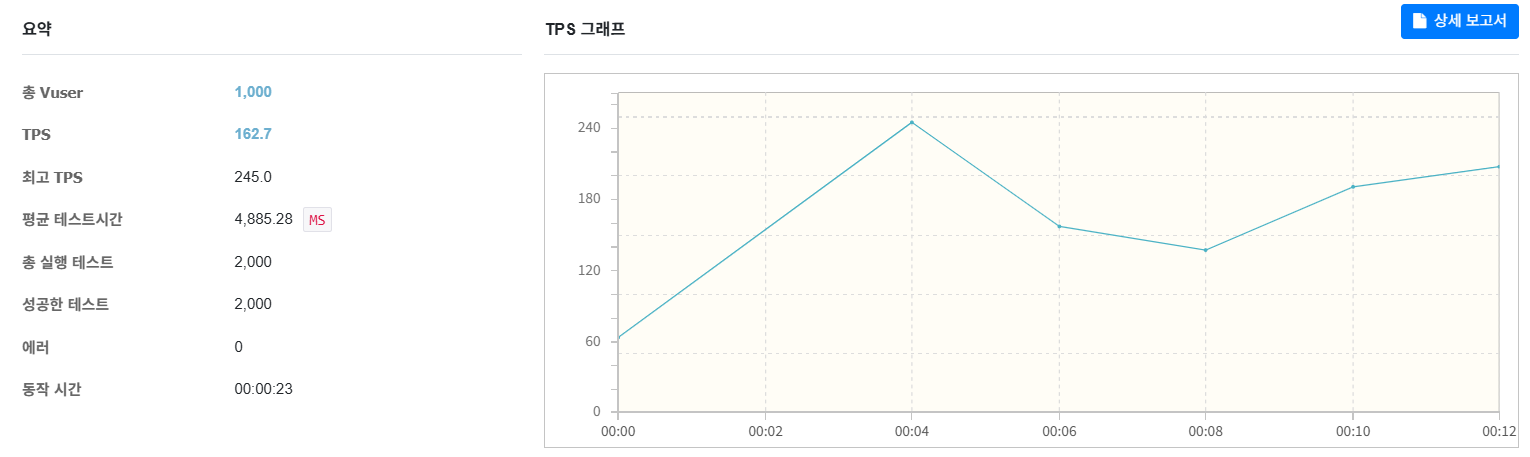
평균 TPS가 119.2 -> 162.7로 무려 36%나 상승했다!
정리
서비스에서 특정 카테고리(예: `FOOD`)에 속한 마켓 목록을 조회하는 쿼리를 개선하고자 했다.
카테고리의 major라는 컬럼의 인덱스를 타지 않아 성능 저하의 문제가 있겠다는 가정 하에 확인을 해보니, 명시적인 캐스팅으로 인한 성능 저하가 있었다는 것을 알게 되었다.
한 줄도 채 되지 않는 코드를 변경함으로 써 2000번의 요청에서 평균 TPS가 36% 상승하는 효과를 보았다.
또한, 카테고리의 ID를 통한 조인에서 이미 1개의 row만 조회하기에 후에 또 인덱스를 통한 조회가 필요없다는 것을 알았고 major 컬럼의 인덱스를 삭제하였다.
마무리
단 한 줄의 코드 차이가 실제 서비스 성능에 큰 영향을 줄 수 있다는 사실을 체감하게 되었다.
이번 경험을 통해, 인덱스는 무조건 성능을 올려주는 만능 도구가 아니라,
오히려 쿼리 흐름에 따라 불필요하거나 무의미해질 수 있다는 점을 배웠다.
앞으로는, 무작정 인덱스를 추가하기보다, 실제 데이터 접근 경로와 조인 흐름을 보고 알맞게 사용해야겠다.
'쿠러미' 카테고리의 다른 글
| [쿠러미] Redis 캐싱을 통한 성능 개선 (1) | 2025.05.28 |
|---|---|
| [쿠러미] 쿼리 최적화를 통한 매장 조회 성능 개선 - 3 (0) | 2025.05.26 |
| [쿠러미] 쿼리 최적화를 통한 조회 성능 개선 시작 - 1 (0) | 2025.05.24 |
| [쿠러미] Redis 분산락 구현, 비관적락 성능 비교 (0) | 2025.05.14 |
| [쿠러미] 쿠폰 발급 시 (동시성 제어 + 중복 체크) 문제해결 (0) | 2025.05.11 |



