서론
저번 글에 쿠폰 발급 동시성 제어의 구현방법 중 비관적락과 유니크 제약조건(중복 체크)를 통해 구현했다.
한 가지 방법이 더 있었는데, 그것은 Redis를 이용한 분산락이었다.
이번 시간에는 분산락을 구현해보고 어떤 방법이 더 성능이나 운영환경에서 좋은 지 트레이드 오프를 고려해보겠다.
분산락이란?
Redis에서 제공하는 락 구현 방식이다. Redis는 명령 처리를 단일 스레드로 처리하기 때문에, 동시에 요청이 들어와도 순차적으로 처리를 하게된다. 하지만 여러 클라이언트가 동시에 명령을 보낼 때 명령의 순서와 원자성을 보장하는 것은 별도의 이야기이며 결론적으로 보장이 안된다.
따라서, 락을 통해 동시성 제어를 해주어야 한다.
Lettuce? Redisson?
락을 구현하기 위해 대표적으로 많이 쓰이는 라이브러리는 Lettuce와 Redisson이 있다.
Lettuce로 분산락을 사용하기 위해서는 setnx, setex 등을 이용해 분산락을 직접 구현해야 한다. 개발자가 직접 retry, timeout과 같은 기능을 구현해 주어야 한다는 번거로움이 있다.
이에 비해 Redisson 은 별도의 Lock interface를 지원한다. 락에 대해 타임아웃과 같은 설정을 지원하기에 락을 보다 안전하게 사용할 수 있다.
락 획득 방식
Lettuce는 분산락 구현 시 setnx, setex과 같은 명령어를 이용해 지속적으로 Redis에게 락이 해제되었는지 요청을 보내는 스핀락 방식으로 동작한다. 요청이 많을수록 Redis가 받는 부하는 커지게 된다.
이에 비해 Redisson은 Pub/Sub 방식을 이용하기에 락이 해제되면 락을 subscribe 하는 클라이언트는 락이 해제되었다는 신호를 받고 락 획득을 시도하게 된다.
따라서, 사용도 쉽고 부하도 덜 받는 Redisson 라이브러리를 사용하게 됐다.
구현
https://helloworld.kurly.com/blog/distributed-redisson-lock/
풀필먼트 입고 서비스팀에서 분산락을 사용하는 방법 - Spring Redisson
어노테이션 기반으로 분산락을 사용하는 방법에 대해 소개합니다.
helloworld.kurly.com
위 블로그를 참해 AOP를 이용한 분산락을 구현했다.(코드가 똑같진 않다!)
Build.gradle
// Redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.redisson:redisson-spring-boot-starter:3.33.0'
우선 build.gradle에 의존성을 추가해주는데 redisson은 정확한 버전을 명시해주어야 한다.
RedisConfig
@Configuration
@EnableCaching
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress(REDISSON_HOST_PREFIX + host + ":" + port);
return Redisson.create(config);
}
}
그 다음 config를 통해 ReddissonClient bean을 생성해 Redis에 접근할 수 있도록 한다.
DistributedLock
@Target(ElementType.METHOD) // 메서드에 사용가능
@Retention(RetentionPolicy.RUNTIME) // AOP 사용가능
public @interface DistributeLock {
String key(); // 락의 키(이름)
TimeUnit timeUnit() default TimeUnit.SECONDS; // 시간 단위
long waitTime() default 5L; // 대기 시간
long leaseTime() default 3L; // 점유 시간
}
분산락이 필요한 메서드에 어노테이션을 붙여 분산락을 시행할 수 있도록 한다. 어노테이션에 들어가는 필수 파라미터는 key이고, 나머지는 디폴트 값이 적용된다.
DistributedLockAop
@Aspect // AOP 클래스를 나타냄
@Component
@RequiredArgsConstructor
@Slf4j
public class DistributeLockAop {
private static final String REDISSON_KEY_PREFIX = "RLOCK_";
private final RedissonClient redissonClient;
private final AopForTransaction aopForTransaction;
// @DistributeLock이 걸린 메소드에 대해 실행
// ProceedJoinPoint는 실제 메소드 호출을 가로채고 실행을 제어할 수 있는 객체
@Around("@annotation(com.appcenter.marketplace.global.annotation.DistributeLock)")
public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature(); // 메소드에 대한 정보를 가져옴
Method method = signature.getMethod(); // 실제 메소드 객체를 가져옴
DistributeLock distributeLock = method.getAnnotation(DistributeLock.class); // @DistributeLock의 속성값 가져옴
String key = REDISSON_KEY_PREFIX + CustomSpringELParser.getDynamicValue(signature.getParameterNames(), joinPoint.getArgs(), distributeLock.key());
RLock rLock = redissonClient.getLock(key); // Reddison의 분산락 객체를 가져옴. 락의 제어권을 가짐
try {
// 락 획득 시도
boolean available =
rLock.tryLock(distributeLock.waitTime(), distributeLock.leaseTime(), distributeLock.timeUnit());
if (!available) {
return false;
}
log.info("get lock success {}" , key);
return aopForTransaction.proceed(joinPoint); // 독립된 트랜잭션으로 비지니스 로직 실행
} catch (InterruptedException e) {
throw new CustomException(StatusCode.LOCK_ACQUISITION_TOO_MANY_REQUESTS); // 락 획득 실패 시 예외처리
} finally {
rLock.unlock();
}
}
}
실제 @DistributeLock 어노테이션이 붙은 메서드에 대해서 수행되는 AOP 클래스이다.
흐름은 다음과 같다.
- 키의 이름으로 RLock 인스턴스를 가져온다.
- 정의된 waitTime까지 획득을 시도한다, 정의된 leaseTime이 지나면 잠금을 해제한다.
- DistributedLock 어노테이션이 선언된 메서드를 별도의 트랜잭션으로 실행한다.
- 종료 시 무조건 락을 해제한다.
여기서 주요하게 볼 부분은 키의 이름을 동적으로 가져오는 CustomSpringELParser ,
별도의 트랜잭션으로 비지니스 로직을 실행하는 AopForTransaction 클래스이다.
CustomSpringELParser
//@DistributeLock의 key를 SpringExpression으로 전달하고 이를 파싱하는 util클래스
public class CustomSpringELParser {
/*
parameterNames: 메소드의 파라미터 이름 배열. 예를 들어, ["userId", "amount"].
args: 메소드 호출 시 전달된 실제 인자 값 배열. 예를 들어, [12345, 100].
key: SpEL 표현식으로 정의된 문자열. 예를 들어, "#userId + '-lock'".
*/
public static Object getDynamicValue(String[] parameterNames, Object[] args, String key) {
ExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
// 파라미터 이름과 값을 컨텍스트에 설정
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
// SpEL 표현식을 평가하여 동적 값을 생성
return parser.parseExpression(key).getValue(context, Object.class);
}
}
@DistributeLock의 key 값을 동적으로 가져올 수 있어,
@DistributeLock(key = "static-lock")
이런식으로 고정된 값을 쓰지 않고,
@DistributedLock(key = "#lockName")
public void shipment(String lockName) {
...
}
메서드의 파라미터 값을 동적으로 쓸 수 있게 된다.
AopForTransaction
@Component
public class AopForTransaction {
// 독립적인 트랜잭션을 만들어 비지니스 로직이 롤백과 상관 없이 락 해제를 하기 위함이다.
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}
[흐름]
락 획득 -> 트랜잭션 획득 -> 비지니스 로직 실행 -> 트랜잭션 커밋/롤백 -> 락 해제
이런 흐름으로 가게끔 해서 비지니스 로직이 롤백되어도 락 해제가 동일하게 이루어지게 했다.
그냥 메서드에 @Transactional을 쓰면 되는거 아닌가?
기본적으로 @Transactional은 AOP를 통해 동작한다.
AOP를 적용하면, 해당 메서드가 속한 Bean 클래스의 프록시를 생성해 해당 메서드의 호출을 제어할 수 있다.
하지만 @DistributeLcok 또한 AOP를 통해 동작하기 때문에, 동시에 적용하게 되면 AOP의 순서가 꼬일 수 있다.
실제로 @Transactional -> @DistributeLock 순으로 적용되어, 커밋전에 락이 풀려, 동시성 제어가 되지 않았다.
따라서 메서드에 붙이지 않고,
joinPoint.proceed();
해당 메서드를 실행하는 코드를 따로 @Transactional을 붙이고 Bean으로 만든 뒤, 호출하면 순서가 락이 먼저 작동하여 동시성제어가 올바르게 동작한다.
테스트
@DistributeLock(key = "'coupon:' + #couponId")
public void issuedCoupon(Long memberId, Long couponId) {
Member member = findMemberById(memberId);
Coupon coupon = findCouponById(couponId);
// 쿠폰의 잔여 갯수가 0개일 경우
if (coupon.getStock() == 0 ){
throw new CustomException(COUPON_SOLD_OUT);
}
// 회원이 이미 해당 쿠폰을 발급받았는지 확인
if (!memberCouponRepository.existCouponByMemberId(member.getId(), coupon.getId())) {
memberCouponRepository.save(MemberCoupon.builder()
.member(member)
.coupon(coupon)
.isUsed(false)
.isExpired(false)
.build());
coupon.reduce();
} else {
throw new CustomException(COUPON_ALREADY_ISSUED);
}
}
서비스 코드는 위와 같이 어노테이션을 붙이기만 했다.
@Test
@DisplayName("쿠폰 다운로드 정합성 테스트")
void testConcurrentReservation() throws InterruptedException {
int numberOfThreads = 10; // 요청 수
ExecutorService executorService = Executors.newFixedThreadPool(10);
CountDownLatch latch = new CountDownLatch(numberOfThreads);
AtomicInteger successCount = new AtomicInteger(0);
List<Exception> exceptions = new ArrayList<>();
List<Long> responseTimes = new ArrayList<>();
// 테스트 시작 시간 기록
long testStartTime = System.nanoTime();
for (int i = 0; i < numberOfThreads; i++) {
executorService.submit(() -> {
long startTime = System.nanoTime(); // 시작 시간 기록
try {
memberCouponService.issuedCoupon(memberId, couponId);
successCount.incrementAndGet();
} catch (PessimisticLockingFailureException e) {
synchronized (exceptions) {
exceptions.add(e);
}
} catch (CustomException e) {
synchronized (exceptions) {
// 다른 예외도 처리
exceptions.add(e);
}
} catch (Exception e) {
synchronized (exceptions) {
// 다른 예외도 처리
exceptions.add(e);
}
} finally {
long endTime = System.nanoTime(); // 종료 시간 기록
long responseTime = endTime - startTime; // 응답 시간 계산
synchronized (responseTimes) {
responseTimes.add(responseTime); // 응답 시간 리스트에 추가
}
latch.countDown();
}
});
}
latch.await();
executorService.shutdown();
// 테스트 종료 시간 기록
long testEndTime = System.nanoTime();
// 전체 테스트 시간 계산 (단위: 밀리초)
long totalTestTimeMillis = (testEndTime - testStartTime) / 1_000_000; // nano -> milliseconds
System.out.println("성공한 다운로드 수: " + successCount.get());
System.out.println("발생한 예외 수: " + exceptions.size());
// 응답 시간 계산
List<Long> responseTimeList = new ArrayList<>(responseTimes);
long fastestResponse = responseTimeList.stream().min(Long::compare).orElse(0L) / 1_000_000; // nanoseconds -> milliseconds
long slowestResponse = responseTimeList.stream().max(Long::compare).orElse(0L) / 1_000_000; // nanoseconds -> milliseconds
double averageResponse = responseTimeList.stream().mapToLong(Long::longValue).average().orElse(0) / 1_000_000.0; // nanoseconds -> milliseconds
exceptions.forEach(ex -> System.out.println("예외 종류: " + ex.getClass().getSimpleName()));
System.out.println("최단 응답 시간: " + fastestResponse + "ms");
System.out.println("최장 응답 시간: " + slowestResponse + "ms");
System.out.println("평균 응답 시간: " + averageResponse + "ms");
// 전체 테스트 시간 출력
System.out.println("전체 테스트 시간: " + totalTestTimeMillis + "ms");
assertEquals(1, successCount.get(), "동시에 하나만 성공해야 합니다");
assertEquals(numberOfThreads - 1, exceptions.size(), "나머지는 예외가 발생해야 합니다");
}
테스트 코드 또한 비관적 락을 구현했을 때와 같이 똑같이 사용하였다.
결과
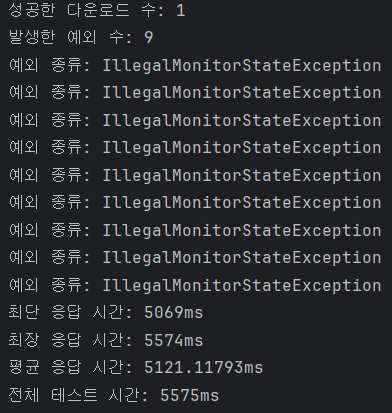
얼핏 봤을 땐 잘 나온 것 같지만 처음 보는 예외가 떴다.
알고보니 쓰레드가 락을 못얻었는데 락을 해제해서 예외가 발생한 것이었다.
그래서 분산락 구현 코드를 다시보니,
try {
// 락 획득 시도
boolean available =
rLock.tryLock(distributeLock.waitTime(), distributeLock.leaseTime(), distributeLock.timeUnit());
if (!available) {
return false;
}
log.info("get lock success {}" , key);
return aopForTransaction.proceed(joinPoint); // 독립된 트랜잭션으로 비지니스 로직 실행
} catch (InterruptedException e) {
throw new CustomException(StatusCode.LOCK_ACQUISITION_TOO_MANY_REQUESTS); // 락 획득 실패 시 예외처리
} finally {
rLock.unlock();
}
락을 획득하지 못해도 finally구문에서 락을 해제한다는 걸 볼 수 있다.
if (rLock.isHeldByCurrentThread()) {
rLock.unlock();
}
그래서 현재 쓰레드가 락을 가지고 있을 때만 해제하도록 변경했다.

동시성 제어도 잘 되고, 중복 체크 관련 이슈도 없다! 모두 어플리케이션 로직에 따른 예외만 있을 뿐이다.
성능 비교
이제 어떤 것이 더 성능이 좋을 지 비교해보자.
시나리오는 500개의 쿠폰이 있을 때, 1000명의 사용자가 동시에 요청하는 상황이다.
먼저, 비관적락과 유니크 제약조건(쿠폰id + 멤버id)의 성능이다.
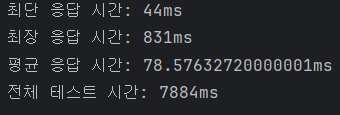
그리고 분산락의 성능이다.

약 3배의 성능차이가 나는 것을 보고 분산락이 좋은게 맞나 생각이 들었다..
일단은 비관적 락으로
db락은 트랜잭션 동안 유지 되고, 이는 곧 커넥션을 계속 점유하게 된다. 따라서 락이 걸려 대기중인 쿼리가 많아지면, 커넥션 풀 내 커넥션이 부족해져 요청이 지연되거나 실패할 수 있다.
Redis 락은 앞단에서 락을 걸어 락 획득 - 트랜잭션 시작 - 트랜잭션 커밋 - 락 해제 순으로 진행이 된다. 따라서 트랜잭션이 순차적으로 실행이 돼, db에서 락을 걸지 않아도 동시성 제어가 이루어지게 된다.
이렇게만 보면 Redis가 좋아보이지만, 우선 스프링부트는 멀티 쓰레드 환경이다. db락의 경우,다수의 트랜잭션을 실행 후 락이 걸린 부분만 제외하고 쿼리를 실행할 수 있다.
하지만 Redis는 무조건 락을 획득해야지 트랜잭션이 시작하게 되어, 단일 쓰레드로 동작하게 된다.
하지만 테스트환경이 단일 DB에 단일 인스턴스이므로 섣부르게 판단하면 안된다.
실제 환경에서는 여러 복합적인 요인이 얽혀있고, 단일 레코드뿐만이 아닌 동시에 여러 테이블에 동시성 제어가 필요한 상황에서는 다를 수 있다.
또한, 다중 인스턴스 / 다중 DB 샤드 구조에서 Redis 분산 락이 더 효과적일 수 있다.
그렇지만 지금은 어지간한 트래픽은 허용가능한 성능빵빵한 학교 서버에 DB와 어플리케이션이 단일로 동작하고, 동시성 제어할 게 쿠폰밖에 없어 비관적 락을 선택하는 걸로 마무리 하겠다.
'쿠러미' 카테고리의 다른 글
| [쿠러미] 쿼리 최적화를 통한 매장 조회 성능 개선 - 2 (0) | 2025.05.25 |
|---|---|
| [쿠러미] 쿼리 최적화를 통한 조회 성능 개선 시작 - 1 (0) | 2025.05.24 |
| [쿠러미] 쿠폰 발급 시 (동시성 제어 + 중복 체크) 문제해결 (0) | 2025.05.11 |
| [쿠러미] FCM 외부 API 이벤트 기반 비동기 처리 & Retry (0) | 2025.04.01 |
| [쿠러미] FCM 구독, 알림 기능 개발 & 비동기 전환 (0) | 2025.03.31 |



